Métricas clásicas para modelos de clasificación
Para evaluar modelos de clasificación, se emplean métricas que permiten medir la eficacia y precisión al distinguir entre diferentes clases de datos. Estas métricas son esenciales para comprender el rendimiento en escenarios reales.
Las métricas clásicas ayudan a identificar cómo un modelo maneja tanto correctamente predicciones positivas como negativas, especialmente cuando los datos están desbalanceados o presentan complejidades específicas.
Conocer y aplicar estas métricas facilita mejorar y comparar modelos, asegurando que el sistema de IA cumpla con los objetivos planteados en diversas aplicaciones.
Precisión, Recall y F1 Score
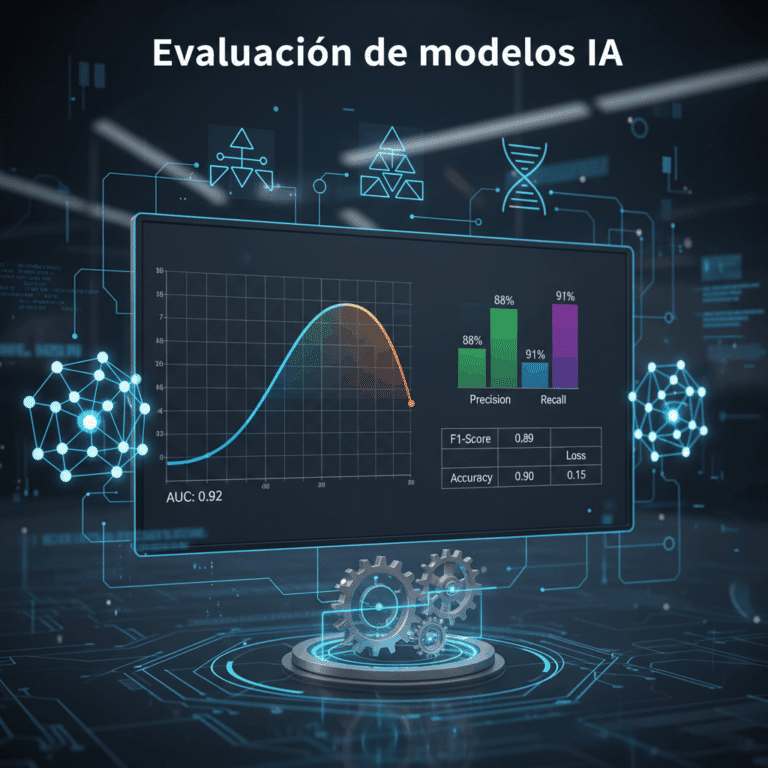
Precisión indica el porcentaje de predicciones correctas sobre el total, ofreciendo una vista global del desempeño del modelo en clasificación.
La recall mide qué tan bien el modelo identifica los casos positivos reales, esencial en dominios donde es crítico no omitir instancias importantes.
El F1 Score combina precisión y recall en una métrica balanceada, útil cuando las clases están desbalanceadas y se busca un equilibrio entre ambos aspectos.
Matriz de confusión y curva ROC-AUC
La matriz de confusión muestra en detalle los aciertos y errores del modelo por clase, ayudando a analizar qué tipos de errores ocurren con mayor frecuencia.
La curva ROC y el valor AUC evalúan la capacidad del modelo para distinguir entre clases, siendo útiles en contextos con decisiones probabilísticas.
El valor AUC resume la curva ROC en un solo número, facilitando la comparación entre modelos respecto a su sensibilidad y especificidad combinadas.
Métricas específicas para modelos generativos de lenguaje
Los modelos generativos de lenguaje requieren métricas especializadas para evaluar la calidad y coherencia de los textos que producen. Estas métricas consideran aspectos semánticos y estructurales del lenguaje.
La evaluación precisa permite mejorar los sistemas de generación de texto y asegurar que el contenido generado sea útil y relevante para los usuarios finales. Por ello, las métricas específicas son clave.
En este contexto, herramientas como BLEU, ROUGE y METEOR son ampliamente utilizadas para medir la similitud entre el texto generado y las referencias humanas.
Evaluación basada en BLEU, ROUGE y METEOR
BLEU mide la precisión de n-gramas, comparando fragmentos de texto generados con textos de referencia para evaluar la exactitud lingüística.
ROUGE, en cambio, está más enfocado en evaluar resúmenes y traducciones, midiendo la superposición entre las palabras o frases generadas y las de referencia.
METEOR incorpora correspondencia semántica y orden de palabras, ajustándose mejor a sinónimos y variaciones lingüísticas, lo que aporta una evaluación más flexible del texto.
Métrica SARI y perplejidad en modelos de lenguaje
La SARI es una métrica que valora la calidad del texto generado, especialmente en tareas de simplificación, comparando el texto original, las referencias y el generado para evaluar cambios útiles.
La perplejidad mide la capacidad predictiva de un modelo de lenguaje, cuantificando la incertidumbre del modelo al predecir una secuencia; valores bajos indican mejor entendimiento.
Estas métricas juntas permiten una evaluación más completa, considerando tanto la calidad lingüística como la probabilidad estadística de las secuencias generadas.
Métricas para agentes de IA y generativos avanzados
Los agentes de inteligencia artificial avanzados requieren métricas específicas que evalúen no solo su precisión, sino también la calidad del contenido generado y su comportamiento ante distintas situaciones.
Estas métricas permiten identificar problemas que van más allá de la simple exactitud, como la generación de información falsa o incoherente, asegurando que los modelos sean útiles y confiables en aplicaciones reales.
El desarrollo y evaluación adecuada de estas métricas es clave para avanzar en la seguridad y efectividad de agentes autónomos y sistemas generativos complejos.
Tasa de alucinaciones y coherencia
La tasa de alucinaciones mide la frecuencia con que un modelo genera información incorrecta o inventada, un problema crítico que afecta la confianza en los sistemas de IA.
Detectar y minimizar estas alucinaciones es vital en aplicaciones sensibles, donde una respuesta errónea puede tener consecuencias negativas importantes.
La coherencia evalúa que las respuestas sean lógicas y consistentes dentro del contexto, garantizando que el contenido generado tenga sentido y fluya naturalmente en la conversación.
La combinación de estas métricas ayuda a mejorar la calidad del output y la experiencia del usuario, evitando desinformación y confusión.
Consistencia, robustez y relevancia
La consistencia se refiere a que el modelo mantenga respuestas estables frente a preguntas similares, evitando contradicciones y manteniendo la lógica interna.
La robustez evalúa la resistencia del modelo ante inputs adversarios o ligeramente modificados, asegurando su funcionamiento fiable en entornos reales y variados.
Por último, la relevancia mide que las respuestas estén fundamentadas en información útil y pertinente para el usuario, aportando valor y precisión en cada interacción.
Importancia en aplicaciones prácticas
Estas métricas son especialmente relevantes para asistentes virtuales, chatbots y sistemas automatizados que deben ofrecer información precisa y coherente en tiempo real.
Una evaluación integral que considere estos aspectos contribuye a crear modelos más confiables y adaptados a las necesidades del usuario final.
Proceso y aplicación de la evaluación de modelos IA
La evaluación de modelos IA debe ser un proceso continuo que asegure su rendimiento constante en diferentes contextos y con datos cambiantes. No basta con pruebas iniciales.
Es fundamental realizar pruebas en escenarios reales para verificar que el modelo se adapta bien a situaciones prácticas y mantiene su efectividad en el uso cotidiano.
Este enfoque garantiza que el modelo no solo sea preciso en datos controlados, sino también fiable y útil en aplicaciones del mundo real.
Evaluación continua y pruebas en escenarios reales
La evaluación continua implica monitorear el desempeño del modelo tras su despliegue para detectar cualquier degradación o desviación en su funcionamiento.
Las pruebas en entornos reales permiten observar cómo reacciona el modelo frente a datos y condiciones no previstas durante su entrenamiento.
De esta forma, se pueden realizar ajustes oportunos que mejoren la robustez y capacidad de generalización del sistema de IA a largo plazo.
Selección de métricas según tipo de modelo y uso
La elección de métricas debe estar alineada con el tipo de modelo y el objetivo específico de su aplicación, pues no todas las métricas son relevantes para cada caso.
Por ejemplo, en clasificación se priorizan precisión y recall, mientras que en modelos generativos el enfoque es la coherencia lingüística o la tasa de alucinaciones.
Combinar diferentes métricas ofrece una visión integral que permite evaluar completas capacidades y limitaciones del modelo.